
A unified analytics + AI platform for distributed TensorFlow, Keras, PyTorch and BigDL on Apache Spark
GitHub
What is Analytics Zoo?
Analytics Zoo provides a unified analytics + AI platform that seamlessly unites Spark, TensorFlow, Keras, PyTorch and BigDL programs into an integrated pipeline; the entire pipeline can then transparently scale out to a large Hadoop/Spark cluster for distributed training or inference.
- Data wrangling and analysis using PySpark
- Deep learning model development using TensorFlow, Keras or PyTorch
- Distributed training/inference on Spark and BigDL
- All within a single unified pipeline and in a user-transparent fashion!
In addition, Analytics Zoo also provides a rich set of analytics and AI support for the end-to-end pipeline, including:
- Easy-to-use abstractions and APIs (e.g., transfer learning support, autograd operations, Spark DataFrame and ML pipeline support, online model serving API, etc.)
- Common feature engineering operations (for image, text, 3D image, etc.)
- Built-in deep learning models (e.g., object detection, image classification, text classification, recommendation, anomaly detection, text matching, sequence to sequence etc.)
- Reference use cases (e.g., anomaly detection, sentiment analysis, fraud detection, image similarity, etc.)
Projects
Analytics Zoo provides a collection of reference user applications and demos, which can be modified or even used off-the-shelf in real world applications. Some are listed below.
*
BigDL: A Distributed Deep Learning Framework for Apache Spark
BigDL allows users to write deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters to process Big Data.

Analytics Zoo: A Unified Data Analytics and AI Platform
Analytics Zoo seamlessly unites TensorFlow, Keras, PyTorch, Spark, Flink and Ray programs into an integrated pipeline, which can transparently scale from laptops to large clusters to process production big data.
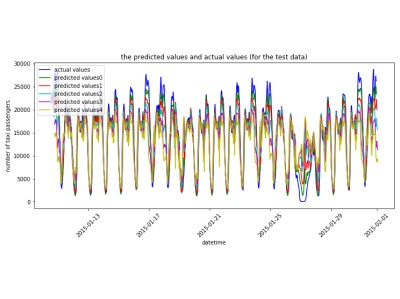
Scalable AutoML for Time Series Prediction Using Ray
It leverages emerging AI technologies (e.g., Ray, hyperparameter optimization, sequence generation models, etc.) to automatically generate feature, select models and tune hyperparameters for time series prediction in a distributed fashion.
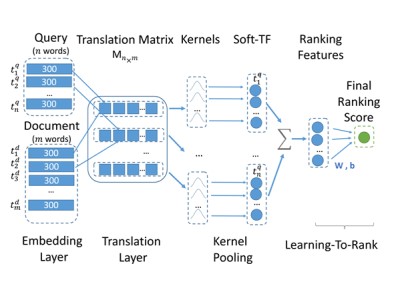
NLP Based Customer Service Chatbot for Azure
Building a customer service chatbot using NLP technologies (e.g., text classification and text matching models) in Analytics Zoo with the Microsoft Azure China team.
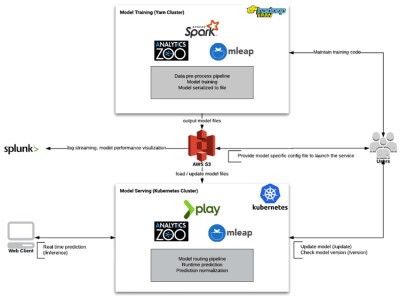
Session-Based Product Recommendation for Office Depot
Building the end-to-end product recommendation pipeline (using session-based recommendation models, Analytics Zoo, MLeap, Play Framework, etc.) on AWS with the Office Depot team.
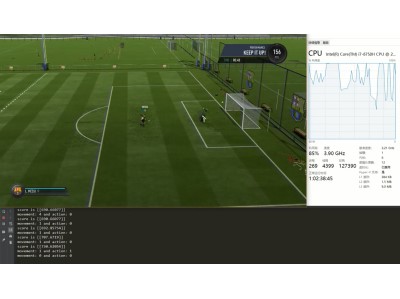
Building AI to play the FIFA video game using distributed TensorFlow
Building an experiment platform using both DRL algorithms (e.g., imitation learning, DQN, policy gradient, etc.) as well as computer vision models (e.g., object detection, object tracking, OCR, etc.) to play FIFA18.
Featured Publications
BigDL: A Distributed Deep Learning Framework for Big Data
This paper presents BigDL (a distributed deep learning framework for Apache Spark), which has been used by a variety of users in the industry for building deep learning applications on production big data platforms. It allows deep learning applications to run on the Apache Hadoop/Spark cluster so as to directly process the production data, and as a part of the end-to-end data analysis pipeline for deployment and management. Unlike existing deep learning frameworks, BigDL implements distributed, data parallel training directly on top of the functional compute model (with copy-on-write and coarse-grained operations) of Spark. We also share real-world experience and "war stories" of users that have adopted BigDL to address their challenges(i.e., how to easily build end-to-end data analysis and deep learning pipelines for their production data).
In ACM Symposium of Cloud Computing conference, SoCC 2019
Build Deep Learning Applications for Big Data Platforms
Recent breakthroughs in artificial intelligence applications have brought deep learning to the forefront of new generations of data analytics. In this tutorial, we will present the practice and design tradeoffs on building large-scale deep learning applications (such as computer vision and NLP), for production data and workflow on Big Data platforms. We will provide an overview of emerging deep learning frameworks for Big Data (e.g., BigDL, TensorFlowOnSpark, Deep Learning Pipelines for Apache Spark, etc.), and present the underlying distributed systems and algorithms. More importantly, we will show how to build and productionize end-to-end deep learning application pipelines for Big Data (on top of Analytics Zoo, a unified analytics + AI platform for distributed TensorFlow, Keras and BigDL on Apache Spark), using real-world use cases (such as Azure, JD.com, World Bank, Midea/KUKA, etc.)
Tutorial in the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-2019)
The HiBench benchmark suite: Characterization of the MapReduce-based data analysis
MapReduce and its popular open source implementation, Hadoop, are moving toward ubiquitous for Big Data storage and processing. Therefore, it is essential to quantitatively evaluate and characterize the Hadoop deployment through extensive benchmarking. We present HiBench, a representative and comprehensive benchmark suite forHadoop, which consists of a set of Hadoop programs including both synthetic micro-benchmarks and real-world applications.
In Proceedings of the 26th International Conference on Data Engineering Whokshops, ICDEW 2010
Automatically partitioning packet processing applications for pipelined architectures
Modern network processors employs parallel processing engines(PEs) to keep up with explosive internet packet processing demands. Most network processors further allow processing engines to be organized in a pipelined fashion to enable higher processing throughput and flexibility. In this paper, we present a novel program transformation technique to exploit parallel and pipelined computing power of modern network processors. Our proposed method automatically partitions a sequential packet processing application into coordinated pipelined parallel subtasks which can be naturally mapped to contemporary highperformance network processors. Our transformation technique ensures that packet processing tasks are balanced among pipeline stages and that data transmission between pipeline stages is minimized. We have implemented the proposed transformation method in an auto-partitioning C compiler product for Intel Network Processors. Experimental results show that our method provides impressive speed up for the commonly used NPF IPv4 forwarding and IP forwarding benchmarks. For a 9-stage pipeline, our auto-partitioning C compiler obtained more than 4X speedup for the IPv4 forwarding PPS and the IP forwarding PPS (for both the IPv4 traffic and IPv6 traffic).
In ACM Sigplan 2005 Conference on Programming Language Design and Implementation(PLDI)
Recent Publications
BigDL: A Distributed Deep Learning Framework for Big Data
In ACM Symposium of Cloud Computing conference, SoCC 2019
Build Deep Learning Applications for Big Data Platforms
Tutorial in the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-2019)
Building Deep Learning Applications on Big Data Platforms
Tutorial In the Conference on Computer Vision and Pattern Recognition, CVPR 2018
Experience from Hadoop Benchmarking with HiBench: From Micro-Benchmarks Toward End-to-End Pipelines
In Proceedings of the 2013 Workshop Series on Big Data Benchmarking
HiTune: Dataflow-Based Performance Analysis for Big Data Cloud
In USENIX Annual Technical Conference (ATC), 2011
The HiBench benchmark suite: Characterization of the MapReduce-based data analysis
In Proceedings of the 26th International Conference on Data Engineering Whokshops, ICDEW 2010
Design Patterns for Internet-Scale Services
In Proceedings of the 25th International Conference on Data Engineering Workshops, ICDEW 2009
Latency Hiding in Multi-Threading and Multi-Processing of Network Applications
In the 16th International Conference on Parallel Architecture and Compilation Techniques, PACT 2007
Automatically partitioning packet processing applications for pipelined architectures
In ACM Sigplan 2005 Conference on Programming Language Design and Implementation(PLDI)
Contact
- lijoan726@gmail.com
- +86 18918828792
- No.880 Zixing Road, Minhang Distract, Shanghai
- Mon-Fri 8:30 to 17:00 or email